В этом подробном руководстве мы расскажем, как настроить проект на PHP с использованием библиотеки php-html-parser для извлечения данных из HTML-контента. Следуя нашим шагам, вы научитесь интегрировать библиотеку, использовать cURL для получения HTML-контента, извлекать нужные данные и экспортировать их в CSV файл.

Шаг #1: Установка PHP HTML Parser
Для начала создайте новый каталог и выполните следующую команду для инициализации проекта Composer:
composer initСледуйте подсказкам, чтобы настроить ваш проект. Вы можете принять значения по умолчанию, просто нажав Enter.
Теперь используйте Composer для скачивания и установки библиотеки php-html-parser:
composer require paquettg/php-html-parserПосле установки библиотеки структура вашего проекта должна выглядеть так:
your-html-parser-project/
├── composer.json
├── composer.lock
└── vendor/
└── autoload.php
└── paquettg/
└── php-html-parser/
├── ...
Если ваши веб-скраперы постоянно блокируются, попробуйте ZenRows API, который решает проблему с прокси и безголовыми браузерами.
Шаг #2: Извлечение HTML
Пришло время извлечь данные. Мы будем использовать демо-страницу Scraping Course E-commerce.
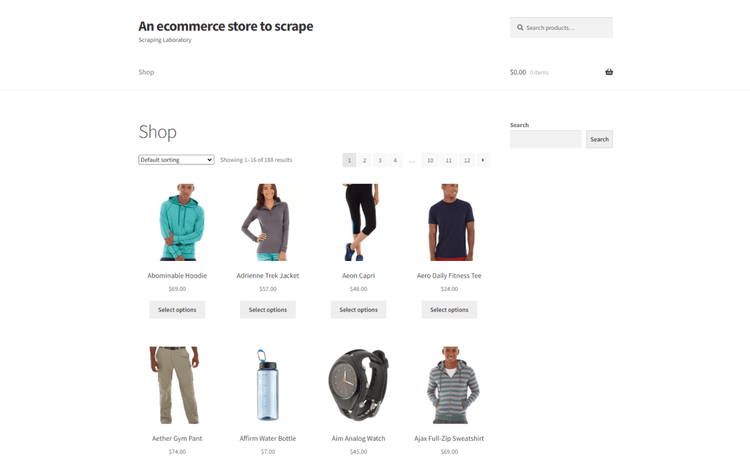
Для этого используем HTTP-клиент cURL для получения контента веб-страницы. Добавьте автозагрузчик Composer для загрузки установленных пакетов и импортируйте класс Dom из библиотеки php-html-parser:
<?php
require "vendor/autoload.php";
use PHPHtmlParser\Dom;
?>Далее инициализируем сессию cURL для получения HTML-контента с целевой страницы (демо-страницы ScrapingCourse E-commerce). Установим необходимые параметры cURL:
CURLOPT_URLдля установки URL для загрузки.CURLOPT_RETURNTRANSFERдля того, чтобы ответ был возвращен как строка.CURLOPT_FOLLOWLOCATIONдля следования за редиректами.CURLOPT_SSL_VERIFYPEERдля игнорирования проверки SSL-сертификата для упрощения.
Пример кода:
<?php
// URL целевой страницы
$url = "https://scrapingcourse.com/ecommerce/";
// инициализируем cURL сессию
$curl = curl_init();
// устанавливаем URL
curl_setopt($curl, CURLOPT_URL, $url);
// возвращаем ответ как строку
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
// следуем за редиректами
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
// игнорируем SSL проверку
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
?>Затем выполняем сессию cURL и сохраняем ответ. Если возникает ошибка, обрабатываем её должным образом. После завершения работы с cURL используем php-html-parser для парсинга полученного HTML-контента и выводим весь HTML.
Пример кода:
<?php
// выполняем cURL сессию
$htmlContent = curl_exec($curl);
// проверяем на ошибки
if ($htmlContent === false) {
$error = curl_error($curl);
echo "Ошибка cURL: " . $error;
exit;
}
// закрываем cURL сессию
curl_close($curl);
// парсим HTML с помощью php-html-parser
$dom = new Dom;
$dom->loadStr($htmlContent);
// выводим весь HTML контент
echo $dom->outerHtml;
?>Этот код выведет весь HTML-контент целевой страницы.
Шаг #3: Парсинг данных
Для парсинга данных из HTML существуют два основных метода: CSS-селекторы и XPath. В данном руководстве мы будем использовать CSS-селекторы, так как они проще и удобнее.
Начнем с извлечения названия продукта. Для этого откроем страницу в браузере, щелкнем правой кнопкой мыши на название продукта и выберем "Инспектировать элемент". В DevTools вы увидите, что названия продуктов находятся в тегах <h2> с классом woocommerce-loop-product__title.
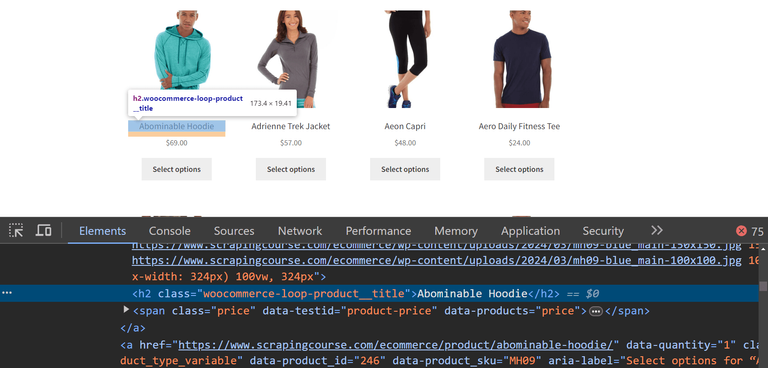
Используем метод find объекта Dom, чтобы найти все элементы, соответствующие данному CSS-селектору.
Пример кода:
<?php
require "vendor/autoload.php";
use PHPHtmlParser\Dom;
// URL целевой страницы
$url = "https://scrapingcourse.com/ecommerce/";
// инициализируем cURL сессию
$curl = curl_init();
// устанавливаем URL
curl_setopt($curl, CURLOPT_URL, $url);
// возвращаем ответ как строку
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
// следуем за редиректами
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
// игнорируем SSL проверку
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
// выполняем cURL сессию
$htmlContent = curl_exec($curl);
// проверяем на ошибки
if ($htmlContent === false) {
$error = curl_error($curl);
echo "Ошибка cURL: " . $error;
exit;
}
// закрываем cURL сессию
curl_close($curl);
// парсим HTML с помощью php-html-parser
$dom = new Dom;
$dom->loadStr($htmlContent);
// извлекаем названия продуктов
$productNames = $dom->find(".woocommerce-loop-product__title");
foreach ($productNames as $name) {
echo "Product Name: " . $name->text . "\n";
}
?>Этот код выведет названия всех продуктов.
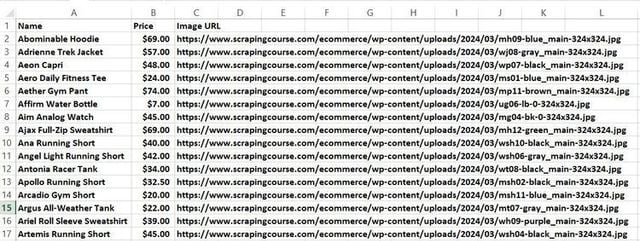
Шаг #4: Экспорт данных в CSV
Теперь, когда мы извлекли данные, пора экспортировать их в CSV файл. Для этого откроем файл для записи, добавим заголовки и запишем данные о каждом продукте.
Пример кода:
<?php
require "vendor/autoload.php";
use PHPHtmlParser\Dom;
// URL целевой страницы
$url = "https://scrapingcourse.com/ecommerce/";
// инициализируем cURL сессию
$curl = curl_init();
// устанавливаем URL
curl_setopt($curl, CURLOPT_URL, $url);
// возвращаем ответ как строку
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
// следуем за редиректами
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
// игнорируем SSL проверку
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
// выполняем cURL сессию
$htmlContent = curl_exec($curl);
// проверяем на ошибки
if ($htmlContent === false) {
$error = curl_error($curl);
echo "Ошибка cURL: " . $error;
exit;
}
// закрываем cURL сессию
curl_close($curl);
// парсим HTML с помощью php-html-parser
$dom = new Dom;
$dom->loadStr($htmlContent);
// извлекаем элементы продуктов
$productElements = $dom->find(".product");
// создаем массив для хранения данных о продуктах
$products = [];
// извлекаем данные о каждом продукте
foreach ($productElements as $element) {
$productName = $element->find(".woocommerce-loop-product__title")->text;
$priceElement = $element->find(".price .woocommerce-Price-amount");
$productPrice = $priceElement ? strip_tags($priceElement->innerHtml) : "N/A";
$productPrice = html_entity_decode($productPrice);
$productImage = $element->find("img")->getAttribute("src");
$products[] = [
"name" => $productName,
"price" => $productPrice,
"image" => $productImage
];
}
// путь для CSV файла
$csvFile = "products.csv";
// открываем файл для записи
$fp = fopen($csvFile, "w");
// добавляем заголовки
fputcsv($fp, ["Name", "Price", "Image URL"]);
// записываем данные о продуктах в файл
foreach ($products as $product) {
fputcsv($fp, [$product["name"], $product["price"], $product["image"]]);
}
// закрываем файл
fclose($fp);
echo "Данные успешно экспортированы в $csvFile\n";
?>Этот код создаст CSV файл с данными о продуктах.
Заключение
В этом руководстве вы узнали, как интегрировать библиотеку php-html-parser в проект PHP, как извлекать данные с веб-страницы с помощью cURL, как парсить данные с помощью CSS-селекторов и как экспортировать эти данные в CSV файл.
Поздравляем, вы освоили основы парсинга HTML с помощью PHP!